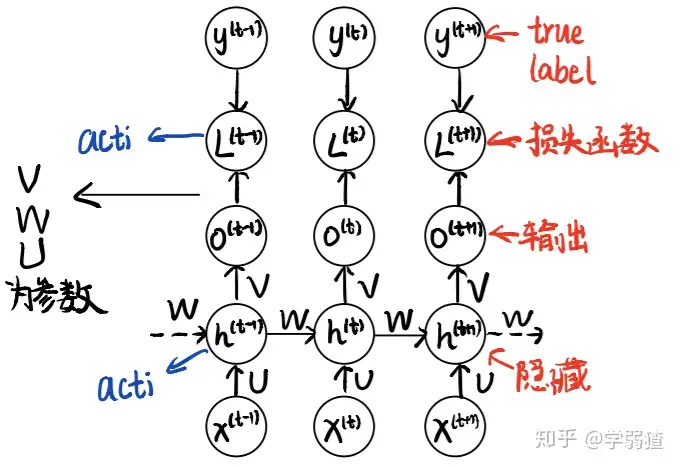
RNN,LSTM,Attention
刚写完卡尔曼滤波那篇,虽然公式耳熟能详,但是还是有很多不理解,再看一篇希望能通透一下头脑
上次看到有外校自动化学长面试遇到Attention问题,当时看到不知道是啥,最近却在推荐里频频刷到,干脆今晚把他大概了解一下吧(现在是2022-10-20-23:50,一会估计还得重整下博客,估计肝又得疼一晚![]()
原文,废话少说,明天奖励自己一顿麦当劳
RNN的中文名是循环神经网络 (Recurrent Neural Network)。考虑到循环就是“一步一步的执行”,也就是说它非常常见于处理序列数据
全连接神经网络会捕捉位置的信息,这在序列模型中不被允许,而RNN可以缓解这个问题
文章讲的还是比较贴近底层的,介绍了人工神经网络ANN的一个简要结构
因为线性化局限所以加入激活函数来制造非线性,输出预测时用softmax函数进行归一化
tm这麦当劳什么鬼,这周给我送的券屈指可数,0元鸡块和可乐至少给我来一打啊,俩月的会员白买了![]()
![]()
![]()
反向传播求梯度老生常谈了,按顺序对各参数从后至前,注意每个参数与哪些前向函数关联,往往是先对一些宏观的函数求梯度,再对这些函数中细微的参数求梯度
双向RNN在于多一个改变方向的隐藏层使得捕捉序列信息的上一步和下一步
LSTM提出是考虑到RNN模型的一个潜在缺陷:梯度消失,梯度爆炸
有意思,上周在《深度学习》看到过梯度消失,印象中与softmax函数有关
LSTM的中文叫长短时记忆网络(long short-term memory),它是一个特殊的节点激活函数
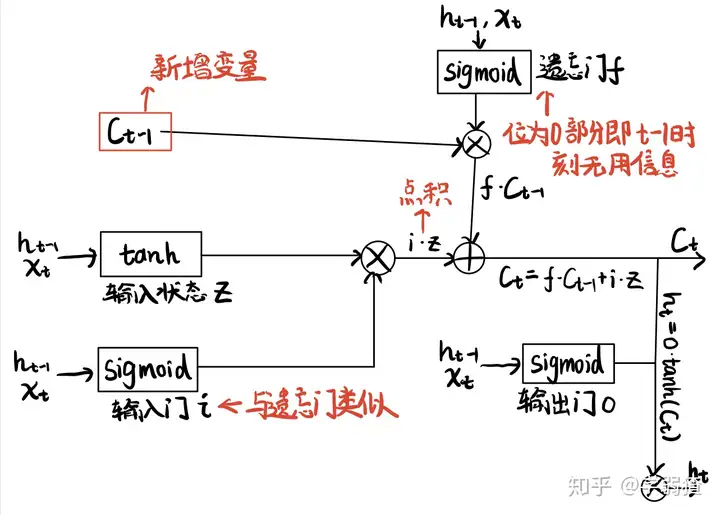
输入门,遗忘门,输出门
每个门都是个sigmoid激活函数,用来衡量重要性
Attention机制
Attention出现之后对于神经网络模型的革新确确实实起了相当大的作用
Attention机制本身是出现在机器翻译中的一个idea
编码器会输出一个固定长度的向量 c (语境向量, context vector),然后解码器就会根据这个向量和之前所有的,已经预测好的翻译词,来通过概率上推断的方法,判断下一个词应该是什么。
我提炼一下,attention在其中的作用就是将原先固定长度的语境常量c加入注意力机制,使得针对每一个位置都给定单独的ci,意味着有限的视野
添加Attention机制的机器翻译模型采用门隐藏单元,设置更新门和复位门,负责保留和遗忘信息
最后把更新方程看明白就行了,训练是他自己的事
这篇文章很长,事实上包含了三个章节,还是挺不错的