Transformer 模型(NLP)
如你所见,本来专心准备考试的我在这写博客
子时读《日本简史》,欲看完一章把作业题复习一遍,突闻疫情已至,校门已封,考试已延,不知道是什么心情,周末到现在复习个大概了,打算周四前做做题牢记知识点,结果打了个水漂。小镇做题家考试讲究一个状态,不知道延期后重拾与现在的状态相比如何。。。
于是乎,脑袋悬空的感觉不好,得找个事干,总结一下中午读的transformer模型吧
回归正题,奉上原文
这篇不是我在专栏找的,是刷推荐的时候看到的,一看transformer,脑子里蹦出哪看到过transformer是NLP算法模型,有人把他套用在CV上获得成功,就不追溯记忆了,抓住机会学一下传统的transformer(都什么年代,可不能只学传统transformer![]() )
)
文章循序渐进的介绍还不错,但是错别字和语句不通还是有点膈应,知乎文章的质量被拉低了,看评论区才知道可能是译文,好吧应该是机翻
关于transformer的结构,令人印象较深的应该是encoder和decoder中的attention注意力学习
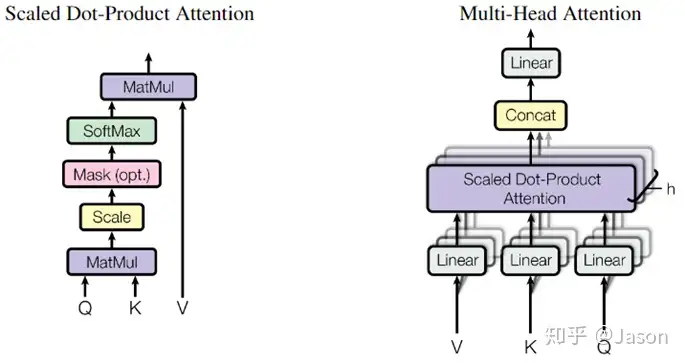
按照attention的流程,他在encoder里的attention是原词乘三个矩阵,然后用第一个结果拿去和每个单词的第二个结果比较,根据比较的注意力(其实是softmax)将第三个结果复合,后面提及的八个QKV在我看来就是增加了分析的维度
乘三个矩阵很抽象,评论区有位老哥说的很好,是把embedding映射到一个更适合做attention的空间,增强表示能力。
接下来就是将attention处理过的数据接入前馈神经网络了
提一嘴,为了考虑到attention对序列位置的不敏感,模型中特意加入了正弦函数体现位置的分量
decoder中经过一轮self-attention后又将其结果和前面encoder的结果进行新一轮attention(把encoder的输出当作Query做一个普通的Attention)
完整过程:
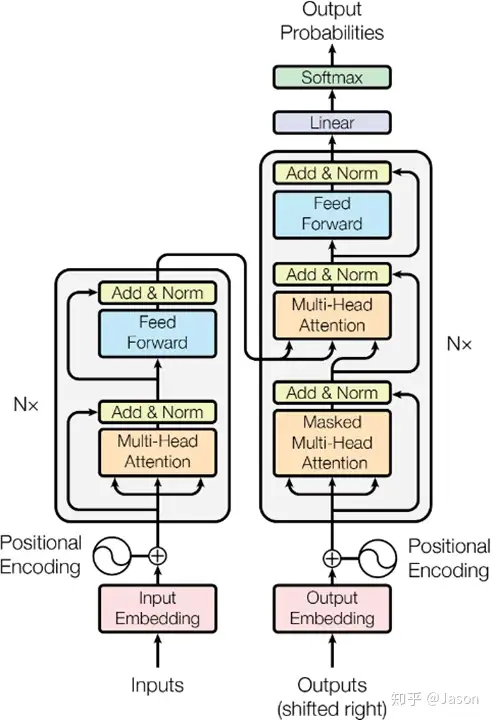
可以注意到每一个处理器都会把输入加一份到输出上,这就是残差神经网络
之前下载了残差神经网络原论文,英文版看一眼没太看懂就搁置了,记得还是个华裔大佬写的,惭愧,有空看看
当然,最后是输出对应字典中每个词的概率,按概率预测结果