对于这些连续的动作,Q学习、深度Q网络等算法是没有办法处理的。那我们怎么输出连续的动作呢?这个时候,“万能”的神经网络又出现了
要输出离散动作,我们就加一个 softmax 层来确保所有的输出是动作概率,并且所有的动作概率和为 1。要输出连续动作,我们一般可以在输出层加一层 tanh 函数。tanh 函数的作用就是把输出限制到 [−1,1] 。
深度确定性策略梯度
在连续控制领域,比较经典的强化学习算法就是深度确定性策略梯度(deep deterministic policy gradient,DDPG)
深度是因为用了神经网络;确定性表示 DDPG 输出的是一个确定性的动作
REINFORCE 算法每隔一个回合就更新一次,但 DDPG 是每个步骤都会更新一次策略网络,它是一个单步更新的策略网络
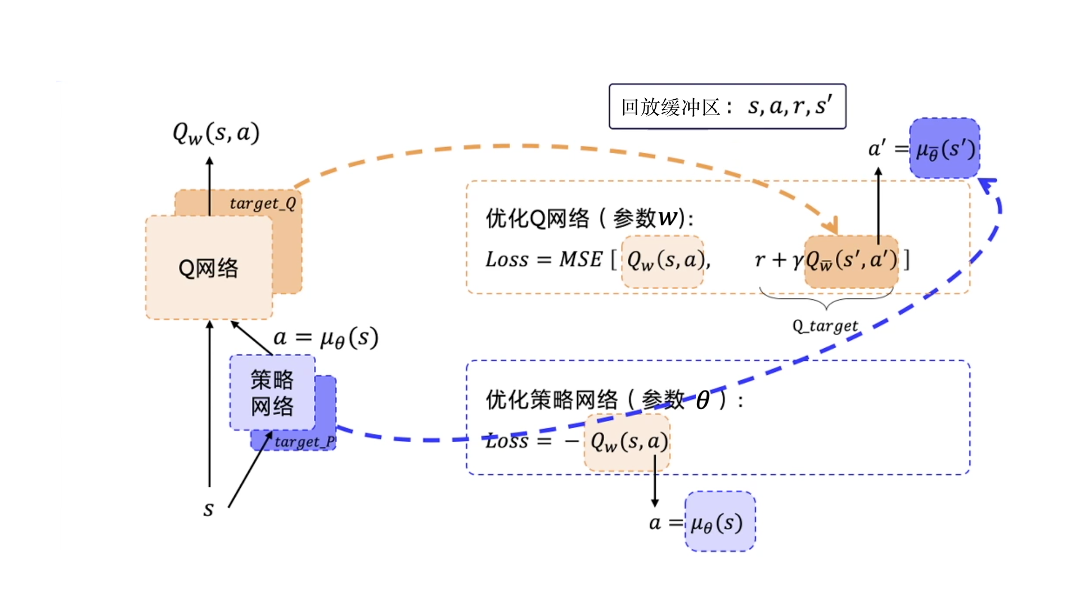
DPG 在 深度Q网络 基础上加了一个策略网络来直接输出动作值,所以 DDPG 需要一边学习 Q 网络,一边学习策略网络
除了策略网络要做优化,DDPG 还有一个 Q 网络也要优化。评论员一开始也不知道怎么评分,它也是在一步一步的学习当中,慢慢地给出准确的分数。
为了使 Q_target 更加稳定,DDPG 分别给 Q 网络和策略网络搭建了目标网络,一共有四个网络
这两个网络也是固定一段时间的参数之后再与评估网络同步最新的参数。
DDPG 使用了经验回放技巧,所以 DDPG 是一个异策略的算法
因为策略是确定的,所以如果智能体使用同策略来探索,在一开始的时候,它很可能不会尝试足够多的动作来找到有用的学习信号。为了让 DDPG 的策略更好地探索,我们在训练的时候给它们的动作加了噪声。
双延迟深度确定性策略梯度
截断的双 Q 学习(clipped double Q-learning)
延迟的策略更新(delayed policy updates)
目标策略平滑(target policy smoothing)
最后看一下伪代码
