模仿学习(imitation learning,IL) 讨论的问题是,假设我们连奖励都没有,要怎么进行更新以及让智能体与环境交互呢?模仿学习又被称为示范学习(learning from demonstration),学徒学习(apprenticeship learning),观察学习(learning by watching)。
假设我们不知道该怎么定义奖励,就可以收集专家的示范。如果我们可以收集到一些示范,可以收集到一些很厉害的智能体(比如人)与环境实际上的交互,就可以考虑采用模仿学习。
—————
行为克隆
行为克隆与监督学习较为相似
专家做什么,智能体就做一模一样的事,这就称为行为克隆。
输入S,希望输出A
专家的示范有限,只观察专家的示范是不够的,还需要结合另一个方法:数据集聚合(dataset aggregation,DAgger)。
希望能够收集专家在各种极端的情况下所采取的行为(开车快要撞墙的时候人类会怎样做)
—————
逆强化学习
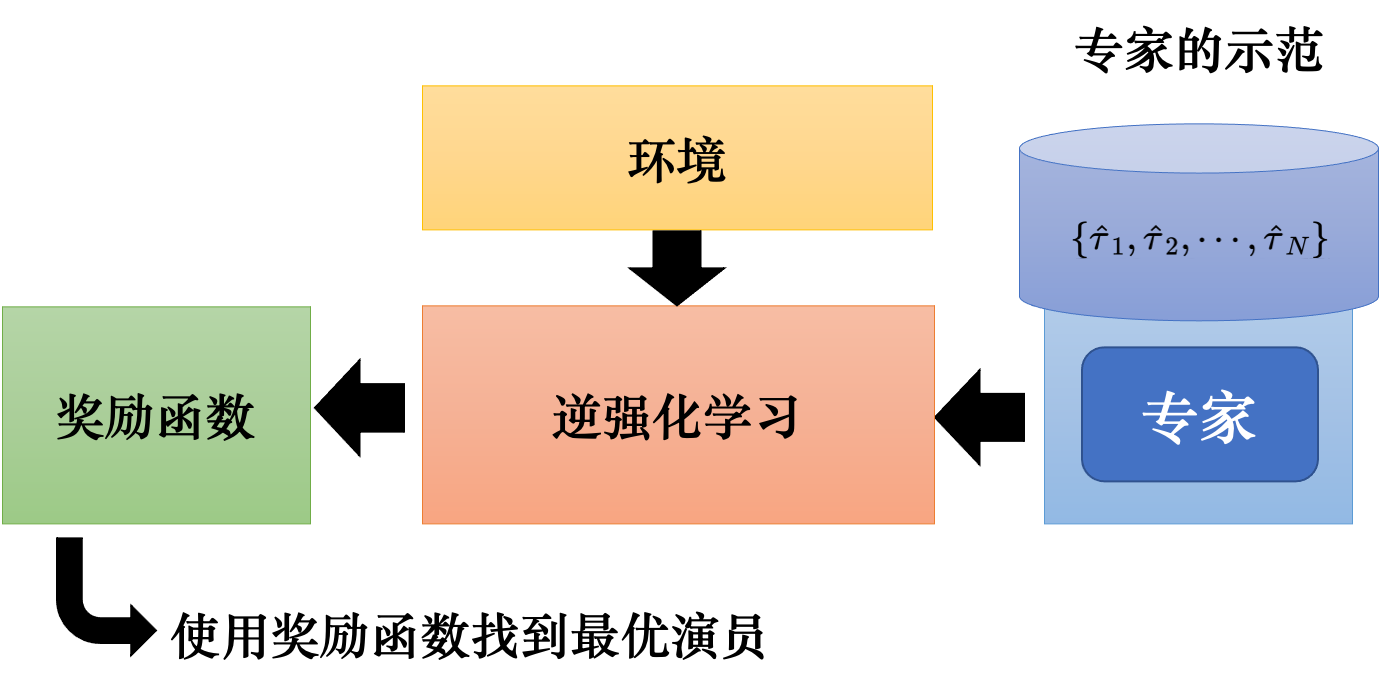
把所有专家的示范收集起来,再使用逆强化学习这一技术。使用逆强化学习技术的时候,智能体是可以与环境交互的。但它得不到奖励,它的奖励必须从专家那里推出来。有了环境和专家的示范以后,可以反推出奖励函数。
强化学习是由奖励函数反推出什么样的动作、演员是最好的。逆强化学习则反过来,我们有专家的示范,我们相信它是不错的,我就反推,专家是因为什么样的奖励函数才会采取这些行为。
也许奖励函数是比较简单的。即虽然专家的行为非常复杂,但也许简单的奖励函数就可以导致非常复杂的行为。
有了新的奖励函数以后,根据这个新的奖励函数,我们就可以得到新的演员,新的演员再与环境交互。它与环境交互以后,我们又会重新定义奖励函数,让专家得到的奖励比演员的大。
逆强化学习就是一种 生成对抗网络 的技术