重要性采样
策略梯度是一个同策略的算法。PPO是策略梯度的变形,它是现在 OpenAI 默认的强化学习算法。
重要性采样(importance sampling) 的概念
对于一个随机变量,我们通常用概率密度函数来刻画该变量的概率分布特性。具体来说,给定随机变量的一个取值,可以根据概率密度函数来计算该值对应的概率(密度)。反过来,也可以根据概率密度函数提供的概率分布信息来生成随机变量的一个取值,这就是采样。因此,从某种意义上来说,采样是概率密度函数的逆向应用。与根据概率密度函数计算样本点对应的概率值不同,采样过程往往没有那么直接,通常需要根据待采样分布的具体特点来选择合适的采样策略。
我们只要对分布p采样足够多次,对分布q采样足够多次,得到的结果会是一样的。但是如果我们采样的次数不够多,因为它们的方差差距是很大的,所以我们就有可能得到差别非常大的结果
近端策略优化
可以通过重要性采样把同策略换成异策略,但Pθ’和Pθ相差太多时重要性采样效果就不好 怎么避免它们相差太多呢?这就是PPO要做的事情。
我们在训练的时候,应多加一个约束:θ和 θ’输出动作的 KL 散度,用于衡量二者相似度
作用类似于正则化
虽然 PPO 的优化目标涉及到了重要性采样,但其只用到了上一轮策略 θ 的数据。PPO 目标函数中加入了 KL 散度的约束,行为策略θ和目标策略θ’非常接近,可认为是同一个策略,因此PPO是同策略算法
PPO 有一个前身:信任区域策略优化(trust region policy optimization,TRPO)
TRPO 与 PPO 不一样的地方是约束所在的位置不一样,PPO 直接把约束放到要优化的式子里面,我们就可以用梯度上升的方法去最大化式(5.6)。但 TRPO 是把 KL 散度当作约束,希望θ和 θ’输出动作的 KL 散度小于σ,在梯度优化很难处理
近端策略优化惩罚
自适应KL散度(adaptive KL divergence)对KL散度前的系数β与KL值的变化构建相关性
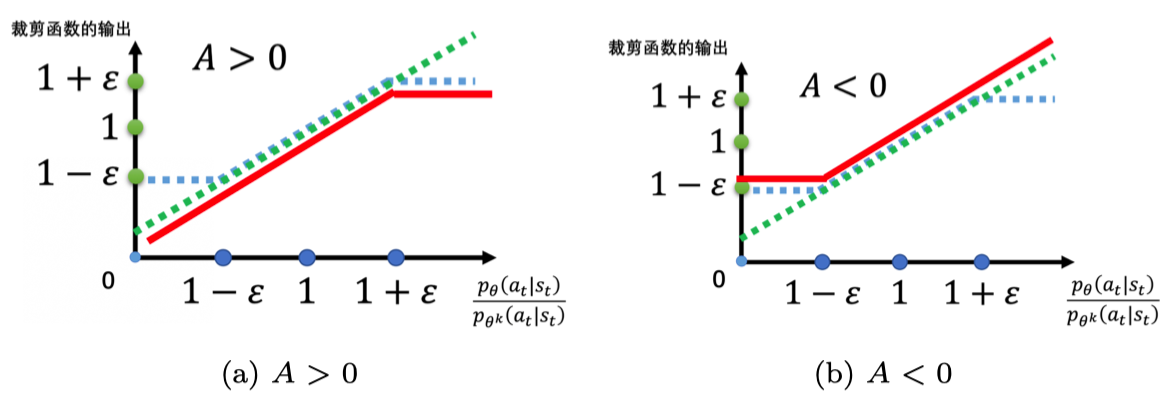
近端策略优化裁剪
clip函数,将Pθ(at|st)/Pθ`(at|st)的值限制在1左右,再使用min使A正负时有相应的松弛界