演员-评论员算法是一种结合策略梯度和时序差分学习的强化学习方法
演员-评论员算法可以进行单步参数更新,不需要等到回合结束才进行更新。在演员-评论员算法里面,最知名的算法就是异步优势演员-评论员算法。如果我们去掉异步,则为优势演员-评论员(advantage actor-critic,A2C)算法
策略梯度问题在于采样次数不多
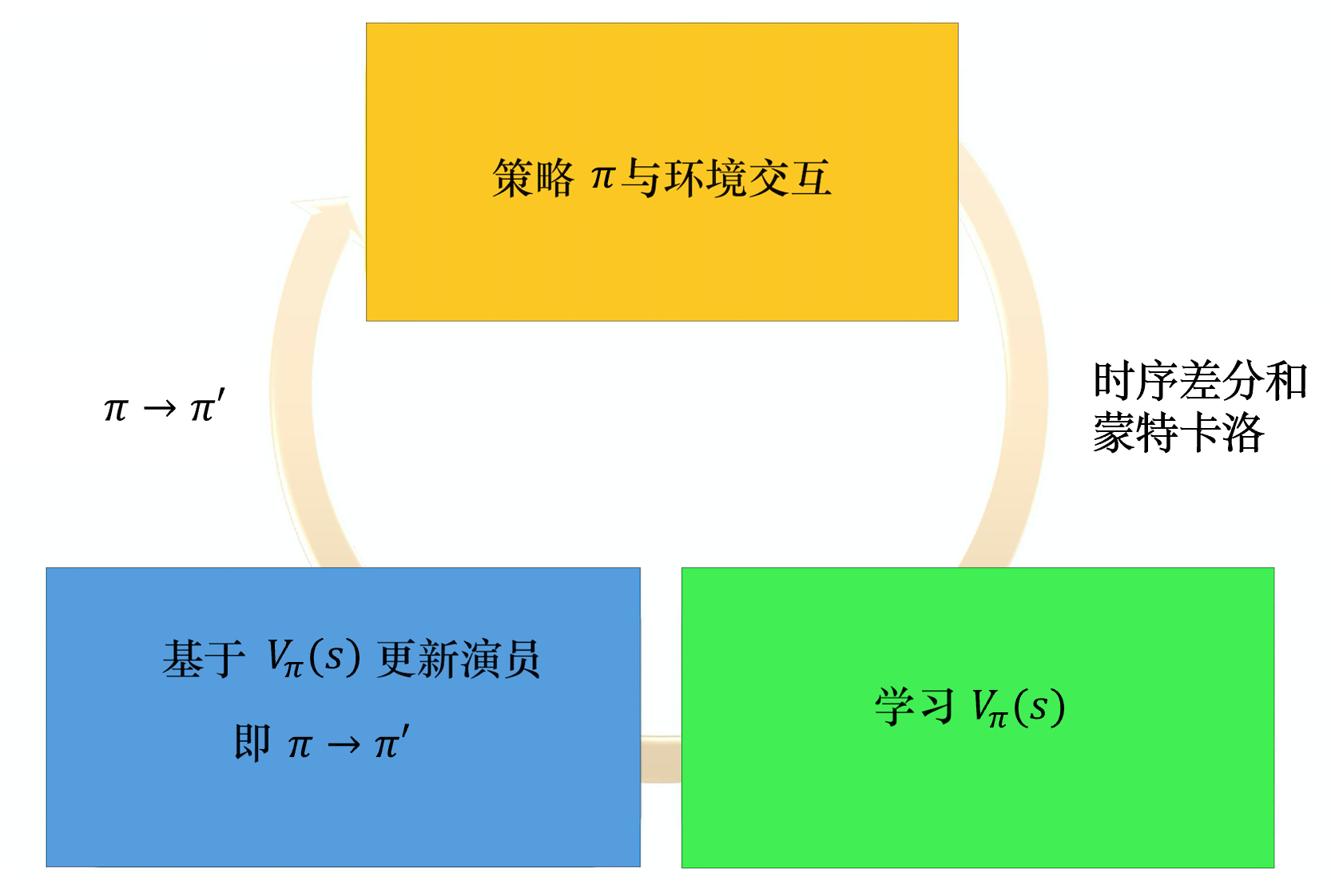
评论员接受一个状态,输出标量V(s),演员接收一个状态,输出动作的分布或者连续的向量
输入的图像非常复杂,通常我们在前期都会用一些卷积神经网络来处理它们,把图像抽象成高级(high level)的信息。把像素级别的信息抽象成高级信息的特征提取器,对于演员与评论员来说是可以共用的。所以通常我们会让演员与评论员共享前面几层,并且共用同一组参数,这一组参数大部分都是卷积神经网络的参数。
—————
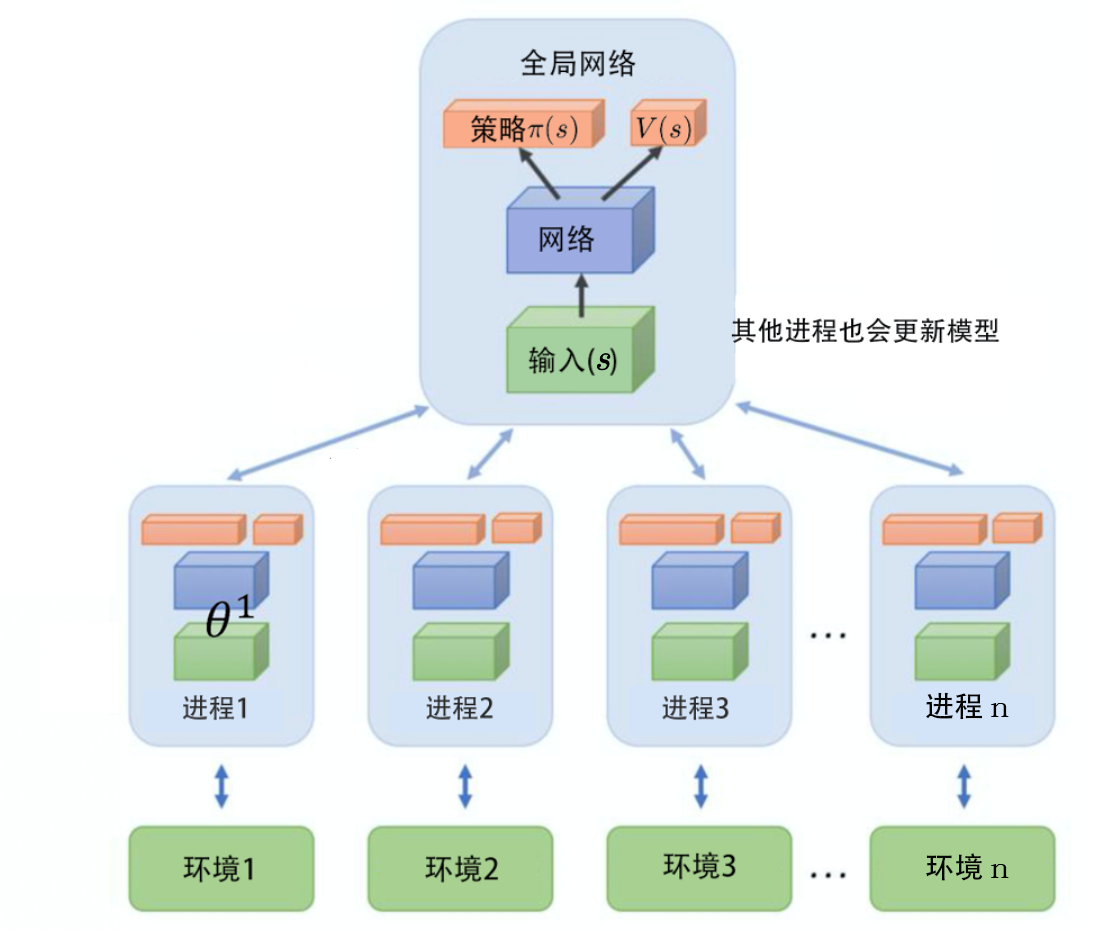
异步优势演员-评论员算法(A3C)的运作流程,异步优势演员-评论员算法一开始有一个全局网络(global network)。全局网络包含策略网络和价值网络,这两个网络是绑定(tie)在一起的,它们的前几个层会被绑在一起。
—————-
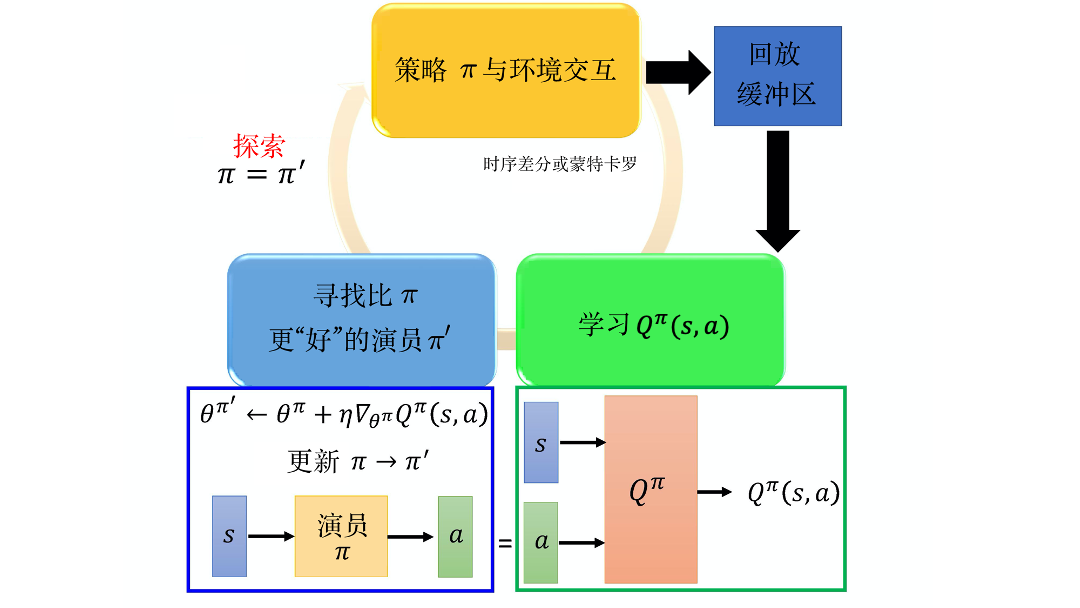
路径衍生策略梯度(pathwise derivative policy gradient)方法。这个方法可以看成 深度Q网络 解连续动作的一种特别的方法,也可以看成一种特别的演员-评论员的方法。
一个观点是:我们可以对原来的深度Q网络 加以改进,学习一个演员来决定动作以解决 arg max 不好解的问题。另外一个观点是:原来的演员-评论员算法的问题是评论员并没有给演员足够的信息,评论员只告诉演员好或不好的,没有告诉演员什么样是好,现在有新的方法可以直接告诉演员什么样的是好的。
Q 是一个网络,接收输入 s 与 a,输出一个值。演员在训练的时候,它要做的事就是接收输入 s,输出 a。把 a 代入 Q 中,希望输出的值越大越好。即有条件的生成对抗网络(conditional GAN)。Q 就是判别器,但在强化学习里就是评论员,演员在 生成对抗网络 里面就是生成器。
————-
GAN 与演员-评论员的方法是非常类似的。