如果环境中的奖励非常稀疏,强化学习的问题就会变得非常困难
设计奖励
环境有一个固定的奖励,它是真正的奖励,但是为了让智能体学到的结果是我们想要的,所以我们刻意设计了一些奖励来引导智能体。
——————-
好奇心
一种技术是给智能体加上好奇心(curiosity),称为好奇心驱动的奖励(curiosity driven reward)
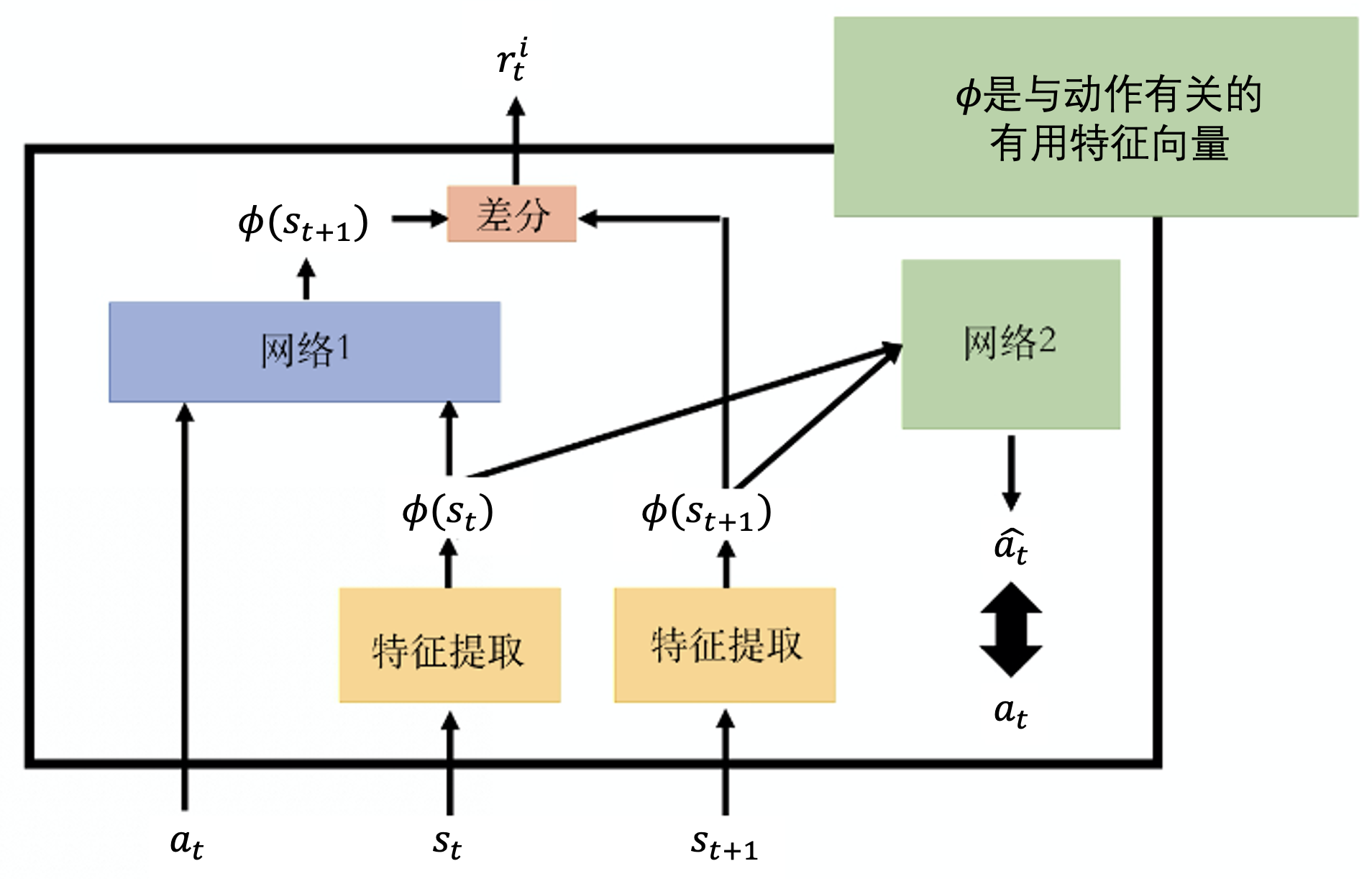
我们会加上一个新的奖励函数——内在好奇心模块(intrinsic curiosity module,ICM),输入状态S1,动作A1和状态S2,输出奖励ri1
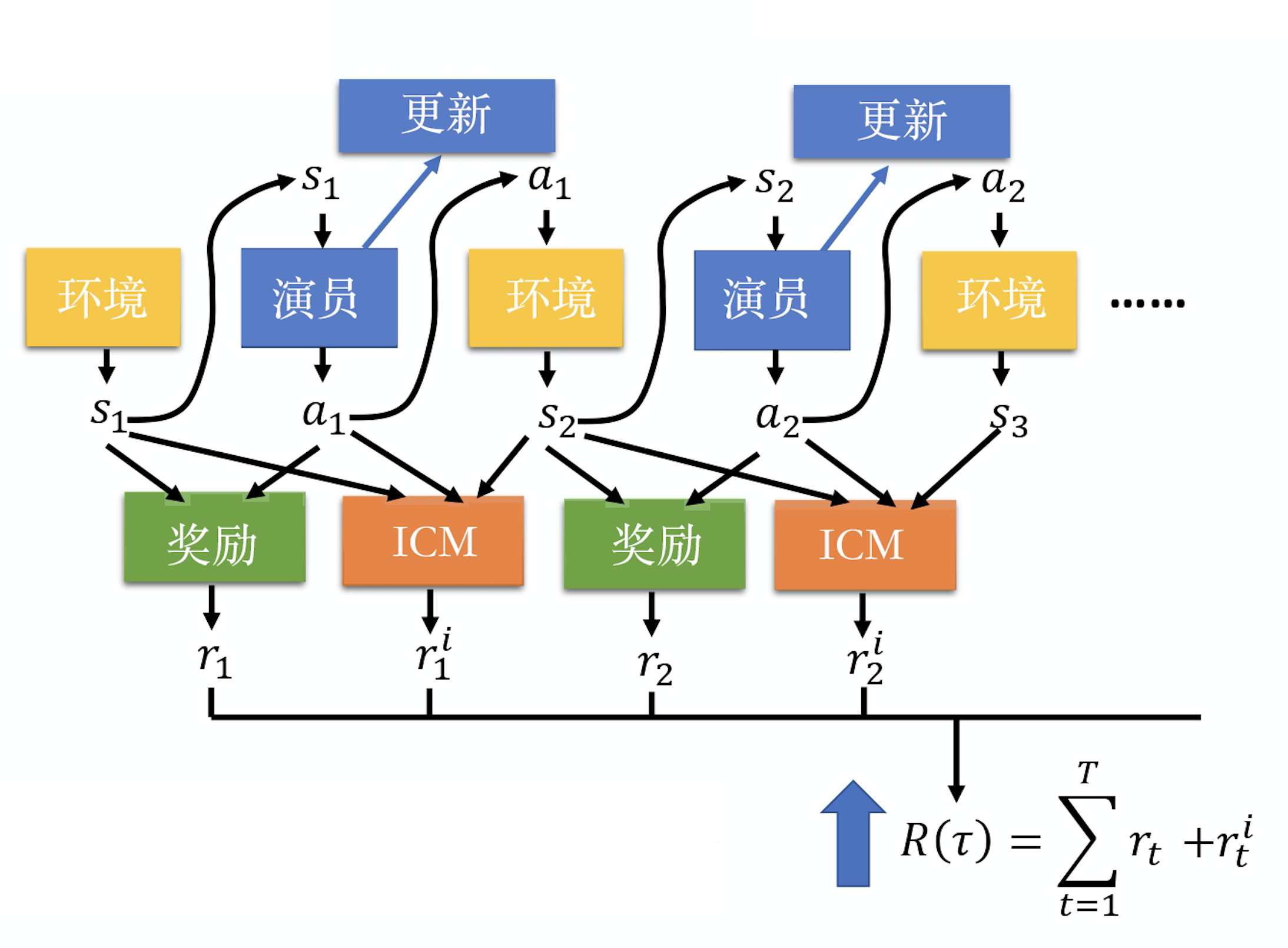
未来的状态越难被预测,得到的奖励就越大。这就是鼓励智能体去冒险
智能体仅仅有好奇心是不够的,还要让它知道,什么事情是真正重要的。智能体仅仅有好奇心是不够的,还要让它知道,什么事情是真正重要的。
———————-
课程学习
在训练循环神经网络 的时候,已经有很多的文献都证明,给智能体先看短的序列,再慢慢给它看长的序列,通常它可以学得比较好。在强化学习里面,我们就是要帮智能体规划它的课程,课程难度从易到难。
逆向课程生成(reverse curriculum generation)。我们可以用一个比较通用的方法来帮智能体设计课程。
——————-
分层强化学习
第三个方向是分层强化学习(hierarchical reinforcement learning,HRL)。分层强化学习是指,我们有多个智能体,一些智能体负责比较高级的东西,它们负责定目标,定完目标以后,再将目标分配给其他的智能体,让其他智能体来执行目标。
PREVIOUSRL学习随记-演员-评论员算法
NEXTRL学习随记-模仿学习